I am trying to access all our historical conversations in Freshdesk in order to do text analytics in python.
However, when I call the Freshdesk API, it only seems to return 30 tickets.
I am also not sure whether there is a simpler way of coding this or if it is necessary to pull a list of all ticket ids and then iterate through the list to get all the conversation body texts each as a sperate API call.
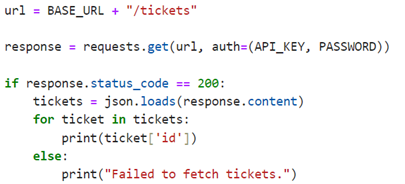
if response.status_code == 200:
tickets = json.loads(response.content)
for ticket in tickets:
print(ticket[‘id’])
else:
print(“Failed to fetch tickets.”)
‘’’
if response.status_code == 200:
conversations = json.loads(response.content)
print([conversation.get(‘body_text’, ‘’) for conversation in conversations])
else:
print(f"Failed to retrieve conversations for ticket {ticket_id}. Status code: {response.status_code}")
‘’’
What you have to consider when iterating through all tickets is, that you have to use the updated_since filter and can only fetch 30.000 tickets with pagination.
So if you have more, you have to use the updated_since accordingly.